
파이썬 판다스로 크롤링을 사용해 웹 사이트 정보를 취득할 수 있습니다.
이번에는 취득한 정보를 csv 파일로 저장하는 예제를 보겠습니다.
크롤링과 csv 파일을 출력은 판다스를 사용하겠습니다.
먼저 데이터를 취득하겠습니다.
import pandas as pd
url = 'https://finance.naver.com/sise/lastsearch2.nhn'
dfs = pd.read_html(url,match='순위',encoding='euc-kr')
# print(dfs[0][['순위', '종목명','현재가']].dropna(how="all"))
dfsNan = dfs[0].dropna(how="all")
print(dfsNan)
결과
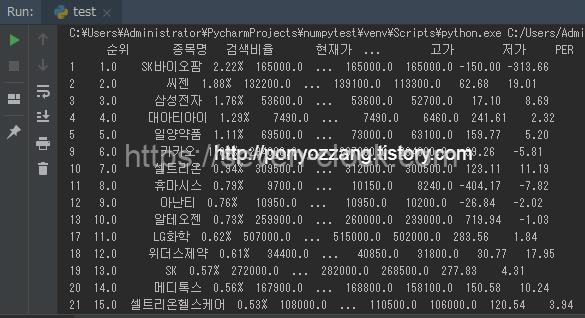
데이터는 문제없이 취득되었습니다.
크롤링에 대한 자세한 설명은 아래를 참조해 주세요.
취득한 데이터를 csv 파일로 저장하기 위해 to_csv() 사용하겠습니다.
import pandas as pd
url = 'https://finance.naver.com/sise/lastsearch2.nhn'
dfs = pd.read_html(url,match='순위',encoding='euc-kr')
# print(dfs[0][['순위', '종목명','현재가']].dropna(how="all"))
dfsNan = dfs[0].dropna(how="all")
dfsNan.to_csv('C:/Users/Administrator/Desktop/python/csv/pandas_sample.csv')
실행하면 지정한 폴더에 csv 파일이 생성됩니다.
생성된 파일을 확인해보겠습니다.
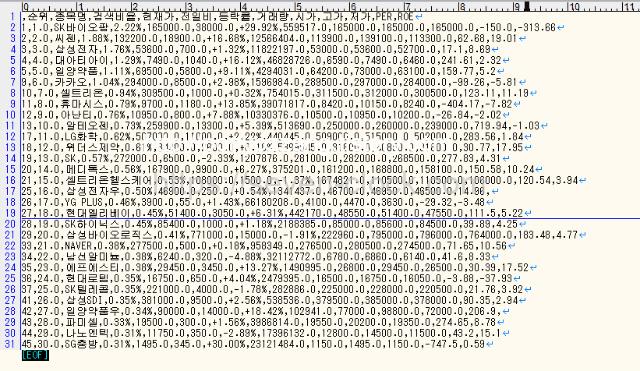
csv 파일에는 크롤링 한 데이터가 출력되었습니다.
특별히 구분을 정해주지 않아도 콤마(,)로 항목별이 구분되어 출력됩니다.
댓글