
파이썬 판다스를 사용해 웹 페이지에 내용을 크롤링 하는 방법을 보겠습니다.
크롤링 취득한 데이터는 DataFrame에 저장해 가공을 하거나 csv 파일로 저장을 할 수 있습니다.
본론으로 들어가 크롤링은 read_html()을 사용해 취득하도록 하겠습니다.
크롤링 할 때 필요한 라이브러리도 미리 설치해두겠습니다.
lxml, html5lib, beautifulsoup4 라이브러리를 설치합니다.
$ pip install lxml html5lib beautifulsoup4
파이참을 사용하는 경우에는 파이참에서 설치해도 됩니다.
웹 크롤링 예제는 네이버 증권을 취득해 보도록 하겠습니다.
네이버 증권에서 국내증시 정보를 취득해 확인해보겠습니다.
import pandas as pd
url = 'https://finance.naver.com/sise/lastsearch2.nhn'
dfs = pd.read_html(url,encoding='euc-kr')
print(len(dfs))결과
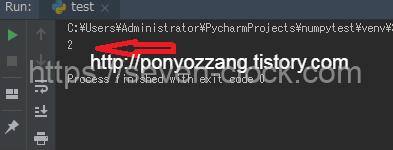
테이블을 2개 취득했습니다.
정보를 취득한 화면을 확인해보겠습니다.
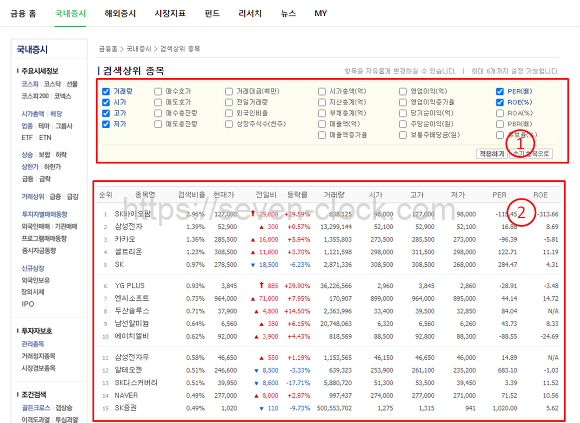
화면에는 2개 테이블이 있습니다.
취득한 결과를 확인했을 때도 2개가 있었습니다.
제대로 취득이 된 거 같습니다.
크롤링 해 취득한 데이터를 담아둔 변수 dfs에는 ①테이블 정보와 ②테이블 정보가 들어있습니다.
변수 dfs에 들어 있는 ②테이블 정보를 출력해보겠습니다.
import pandas as pd
url = 'https://finance.naver.com/sise/lastsearch2.nhn'
dfs = pd.read_html(url,encoding='euc-kr')
print(dfs[1])
결과
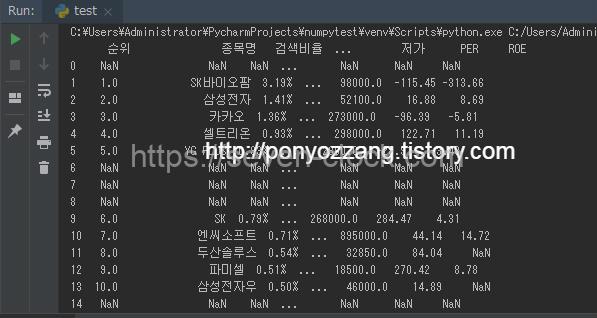
주식 정보가 출력되었습니다.
출력된 항목 중에 표시하고 싶은 목록만 설정하고 싶은 경우가 있습니다.
순위, 종목명, 현재가 항목만 표시하도록 하겠습니다.
import pandas as pd
url = 'https://finance.naver.com/sise/lastsearch2.nhn'
dfs = pd.read_html(url,encoding='euc-kr')
print(dfs[1][['순위', '종목명','현재가']])
결과
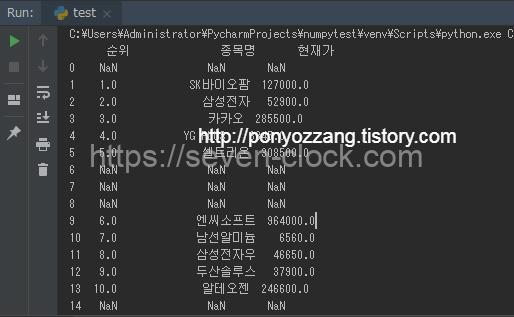
순위, 종목명, 현재가 항목만 출력되었습니다.
출력한 결과 중에 NaN 값이 포함되 보기에 조금 안좋습니다.
NaN 부분을 제거해서 출력하는 방법을 보겠습니다.
import pandas as pd
url = 'https://finance.naver.com/sise/lastsearch2.nhn'
dfs = pd.read_html(url,encoding='euc-kr')
print(dfs[1][['순위', '종목명','현재가']].dropna(how="all"))
결과
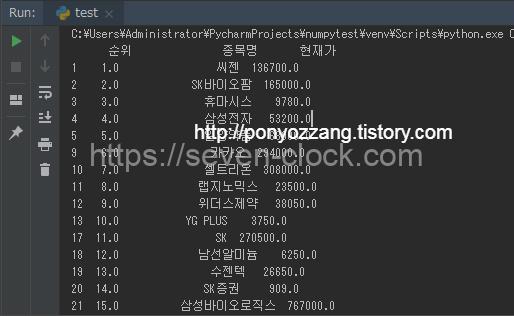
dropna을 사용해 모든 행에 NaN값이 존재하는 행을 모두 삭제하고 출력했습니다.
크롤링 한 페이지에서 취득한 테이블이 1개나 2개 정도라면 원하는 부분을 쉽게 찾을 수 있습니다.
하지만 5개, 10개 등 많은 테이블이 존재하는 페이지를 크롤링 한 경우에는 찾는게 번거로워집니다.
이러한 경우에는 match를 사용 편리하게 취득할 수 있습니다.
import pandas as pd
url = 'https://finance.naver.com/sise/lastsearch2.nhn'
dfs = pd.read_html(url,match='순위',encoding='euc-kr')
print(len(dfs))
결과
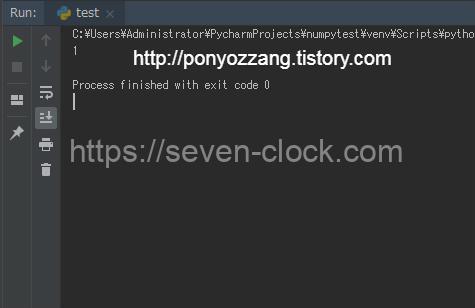
match를 사용해 취득하고 싶은 항목을 지정합니다.
결과에는 지정한 문자열이 포함된 표만 취득하게 됩니다.
import pandas as pd
url = 'https://finance.naver.com/sise/lastsearch2.nhn'
dfs = pd.read_html(url,match='순위',encoding='euc-kr')
print(dfs[0][['순위', '종목명','현재가']].dropna(how="all"))
결과
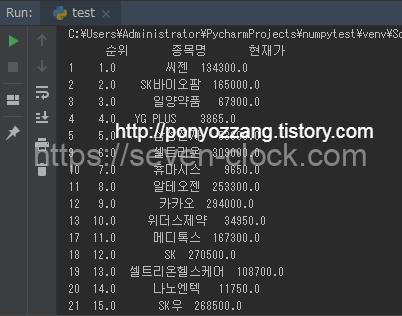
match를 사용해 취득한 결과도 제대로 표시되고 있습니다.
크롤링 할 페이지에 표가 많은 경우에는 match를 사용해 간편하게 취득하는 것이 좋습니다.
댓글