
파이썬에서 DataFrame으로 작성한 데이터를 엑셀파일(xlsx, xls)로 저장하는 방법을 알아보겠습니다.
엑셀 파일로 데이터를 저장하기 위해서는 to_excel() 메서드를 사용합니다.
to_excel()사용 방법을 예제를 통해 알아보겠습니다.
xlwt, openpyxl 설치
to_excel()를 사용하면 내부에서는 xlwt, openpyxl 라이브러리를 사용합니다.
만약 라이브러리 설치가 되지 않았다면 엑셀 파일을 저장할 때 에러가 발생합니다.
import openpyxl
ModuleNotFoundError: No module named 'openpyxl'
파이참을 사용하는 경우에는 라이브러리를 검색해 추가를 하면 됩니다.
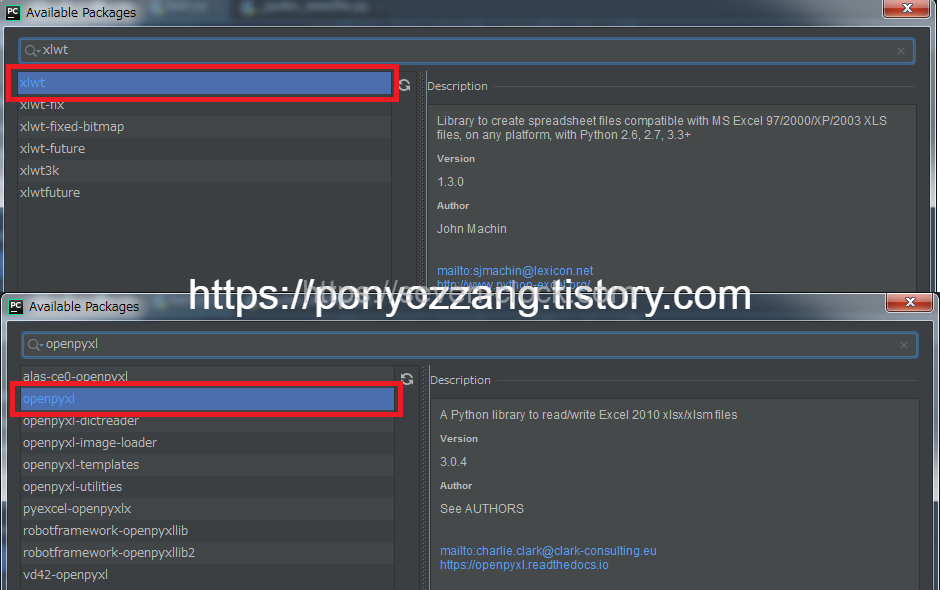
커맨드로 인스톨하는 경우에는 pip를 사용합니다.
$ pip install xlwt
$ pip install openpyxl환경에 따라 pip3를 사용해야 하는 경우도 있습니다.
엑셀 파일 쓰기
DataFrame에 데이터를 작성해 엑셀 파일로 출력하는 예제를 살펴보겠습니다.
import pandas as pd
import openpyxl
df = pd.DataFrame([[11, 21, 31], [12, 22, 32], [31, 32, 33]],
index=['one', 'two', 'three'], columns=['a', 'b', 'c'])
print(df)
# a b c
# one 11 21 31
# two 12 22 32
# three 31 32 33
# 엑셀 파일 출력
df.to_excel('C:/Users/Administrator/Desktop/python/excel/export_sample.xlsx', sheet_name='new_name')
DataFrame에 작성한 데이터가 엑셀 파일로 출력되었습니다.
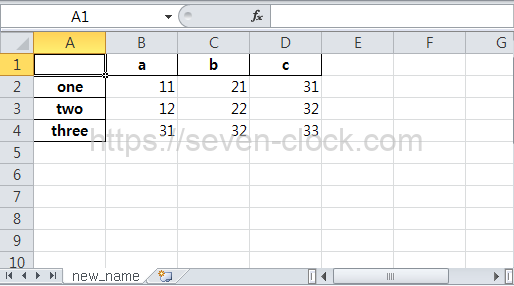
to_excel() 메서드 첫 번째 인수에는 엑셀 파일을 생성할 경로와 파일 이름을 지정합니다.
지정한 경로에 파일이 없는 경우에는 파일을 새로 만듭니다.
파일이 존재하는 경우에는 덮어쓰기를 합니다.
덮어쓰기를 하는 경우에는 기존 데이터는 삭제됩니다.
두 번째 인수에는 sheet_name에 시트 이름을 지정합니다.
생략하는 경우에는 Sheet1이라는 이름으로 시트가 생성됩니다.
index, columns
엑셀 파일을 생성할 때 index(행 이름)와 colunms(컬럼 이름)이 필요 없는 경우에는 index와 colunms를 False로 설정합니다.
import pandas as pd
import openpyxl
df = pd.DataFrame([[11, 21, 31], [12, 22, 32], [31, 32, 33]],
index=['one', 'two', 'three'], columns=['a', 'b', 'c'])
print(df)
# a b c
# one 11 21 31
# two 12 22 32
# three 31 32 33
# 엑셀 파일 출력
df.to_excel('C:/Users/Administrator/Desktop/python/excel/export_sample.xlsx', sheet_name='new_name', index=False, header=False)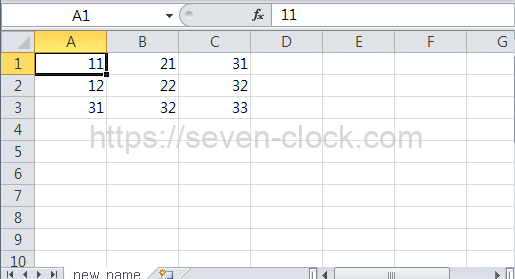
인덱스와 컬럼은 출력되지 않았습니다.
여러개 시트 만들기
엑셀 파일에 데이터를 저장할 때 여러개 시트를 만들 수 있습니다.
DataFrame이 여러개 이거나 또는 같은 내용을 여러 시트에 작성하고 싶은 경우 ExcelWriter를 사용합니다.
예제로 DataFrame을 2개 준비해 엑셀 파일에도 2개 시트를 만들도록 하겠습니다.
import pandas as pd
import openpyxl
df = pd.DataFrame([[11, 21, 31], [12, 22, 32], [31, 32, 33]],
index=['one', 'two', 'three'], columns=['a', 'b', 'c'])
print(df)
# a b c
# one 11 21 31
# two 12 22 32
# three 31 32 33
df2 = df[['a', 'c']]
print(df2)
# a c
# one 11 31
# two 12 32
# three 31 33
# 엑셀 파일 출력
# 여러개 시트 생성
with pd.ExcelWriter('C:/Users/Administrator/Desktop/python/excel/export_sample.xlsx') as writer:
df.to_excel(writer, sheet_name='sheet1')
df2.to_excel(writer, sheet_name='sheet2')
변수 df에 저장된 값은 sheet1 시트에, df2에 저장된 값은 sheet2 시트에 출력되었습니다.
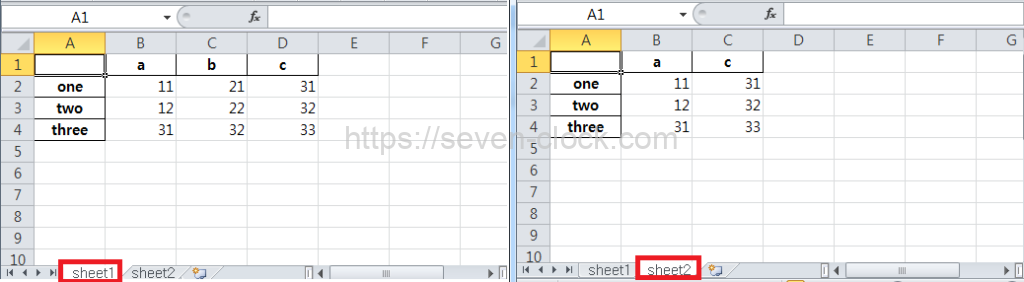
ExcelWriter() 함수에는 파일 경로와 파일 이름을 지정해 ExcelWriter 오브젝트를 생성합니다.
생성한 오브젝트를 to_excel() 메서드 첫 번째 인수로 설정합니다.
with 블럭을 사용하면 writer.save()와 writer.close()를 호출하지 않아도 됩니다.
엑셀 파일 덮어 쓰기
ExcelWriter 오브젝트의 book 속성에 poenpyxl을 사용해 읽어들인 Workbook 오브젝트를 지정하면, 기존 Excel 파일을 새로운 시트로써 DataFrame을 추가할 수 있습니다.
단, openpyxl를 사용해서 처리하기 때문에 xlsx 파일만 가능합니다.
import pandas as pd
import openpyxl
df = pd.DataFrame([[11, 21, 31], [12, 22, 32], [31, 32, 33]],
index=['newone', 'newtwo', 'newthree'], columns=['newa', 'newb', 'newc'])
print(df)
# newa newb newc
# newone 11 21 31
# newtwo 12 22 32
# newthree 31 32 33
df2 = df[['newa', 'newc']]
print(df2)
# newa newc
# newone 11 31
# newtwo 12 32
# newthree 31 33
# 엑셀 파일 덮어 쓰기
path = 'C:/Users/Administrator/Desktop/python/excel/export_sample.xlsx'
with pd.ExcelWriter(path) as writer:
writer.book = openpyxl.load_workbook(path)
df.to_excel(writer, sheet_name='new_sheet1')
df2.to_excel(writer, sheet_name='new_sheet2')기존에 작성했던 sheet1과 sheet2 시트가 삭제되지 않고 남아있습니다.
새로 지정한 new_sheet1과 new_sheet2 시트가 추가되었습니다.
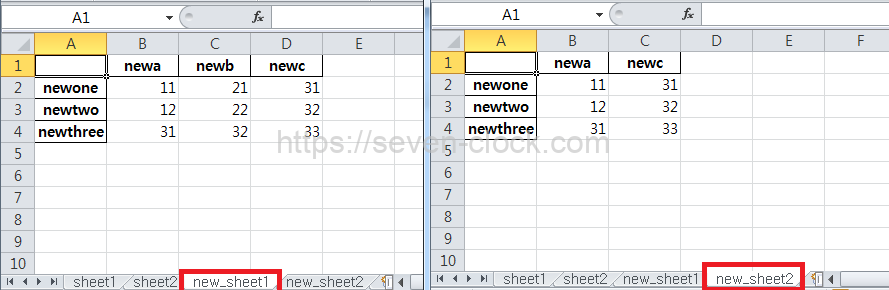
to_excel()를 사용해 실행하면 sheet1과 sheet2 시트는 삭제됩니다.
댓글