
파이썬으로 엑셀 파일에 있는 데이터를 read_excel()를 사용해 취득해올 수 있습니다.
특별히 설정을 하지 않으면 지정한 엑셀 파일에 있는 시트 내용을 모두 취득해옵니다.
만약 취득하고 싶지 않은 열 또는 행이 있다면 skiprows 또는 skiprows, usecols를 사용해 원하는 데이터만 취득할 수 있습니다.
read_excel()를 사용해 원하는 엑셀에서 일부분만 취득하는 방법을 보겠습니다.
read_excel() 자세한 사용 방법은 아래를 참조해 주세요.
샘플 데이터를 준비하겠습니다.
엑셀에는 아래와 같은 데이터를 입력했습니다.
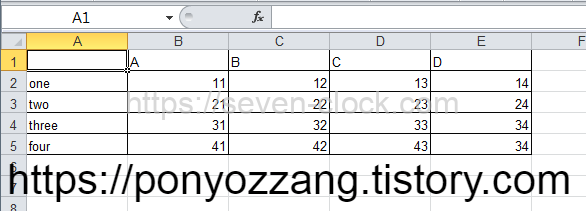
usecols 열 취득
usecols를 사용해 엑셀 시트에서 원하는 열만 취득할 수 있습니다.
usecols에는 취득하고 싶은 열을 리스트 형태로 설정합니다.
import pandas as pd
import openpyxl
df_use_skip = pd.read_excel('C:/Users/Administrator/Desktop/python/excel/excel_sample.xlsx', usecols=[0, 1, 3])
print(df_use_skip)
# Unnamed: 0 A C
# 0 one 11 13
# 1 two 21 23
# 2 three 31 33
# 3 four 41 43
usecols에 지정한 컬럼은 인덱스 형식으로 설정합니다.
A컬럼은 0부터 시작합니다.
엑셀 파일 sheet1 시트에서 A, B ,D 열에 있는 값을 취득했습니다.
skiprows 행 취득
엑셀 파일에서 원하는 행만 취득하기 위해서는 skiprows를 설정합니다.
정확하게 보면 원하는 행만 취득하는 것이 아닌 취득하고 싶은 않은 행을 가져오지 않습니다.
import pandas as pd
import openpyxl
df_use_skip = pd.read_excel('C:/Users/Administrator/Desktop/python/excel/excel_sample.xlsx', skiprows=[1])
print(df_use_skip)
# Unnamed: 0 A B C D
# 0 two 21 22 23 24
# 1 three 31 32 33 34
# 2 four 41 42 43 44skiprows에는 취득하고 싶은 않은 행을 리스트 형태로 설정합니다.
엑셀 첫 번째 행 인덱스는 0부터 시작합니다.
1을 지정했기 때문에 2번째 행인 one이 작성된 행을 취득하지 않았습니다.
skipfooter 마지막행 스킵
skipfooter를 설정 하면 엑셀 시트에 있는 데이터중 마지막 행을 취득하지 않습니다.
import pandas as pd
import openpyxl
df_use_skip = pd.read_excel('C:/Users/Administrator/Desktop/python/excel/excel_sample.xlsx', skipfooter=1)
print(df_use_skip)
# Unnamed: 0 A B C D
# 0 one 11 12 13 14
# 1 two 21 22 23 24
# 2 three 31 32 33 34
skipfooter에는 숫자 타입의 값을 설정합니다.
지정한 값만큼 마지막 행을 취득하지 않습니다.
예제에서는 1을 지정해 마지막 1행을 취득하지 않았지만 2를 지정하면 마지막 2행을 취득하지 않습니다.
read_excel() 함수에 usecols, skiprows, skipfooter를 조합해 원하는 곳에 있는 데이터만 취득이 가능합니다.
import pandas as pd
import openpyxl
df_use_skip = pd.read_excel('C:/Users/Administrator/Desktop/python/excel/excel_sample.xlsx',usecols=[0, 1, 3], skiprows=[1], skipfooter=1)
print(df_use_skip)
# Unnamed: 0 A C
# 0 two 21 23
# 1 three 31 33
댓글